真实面经题目 · 原创解析
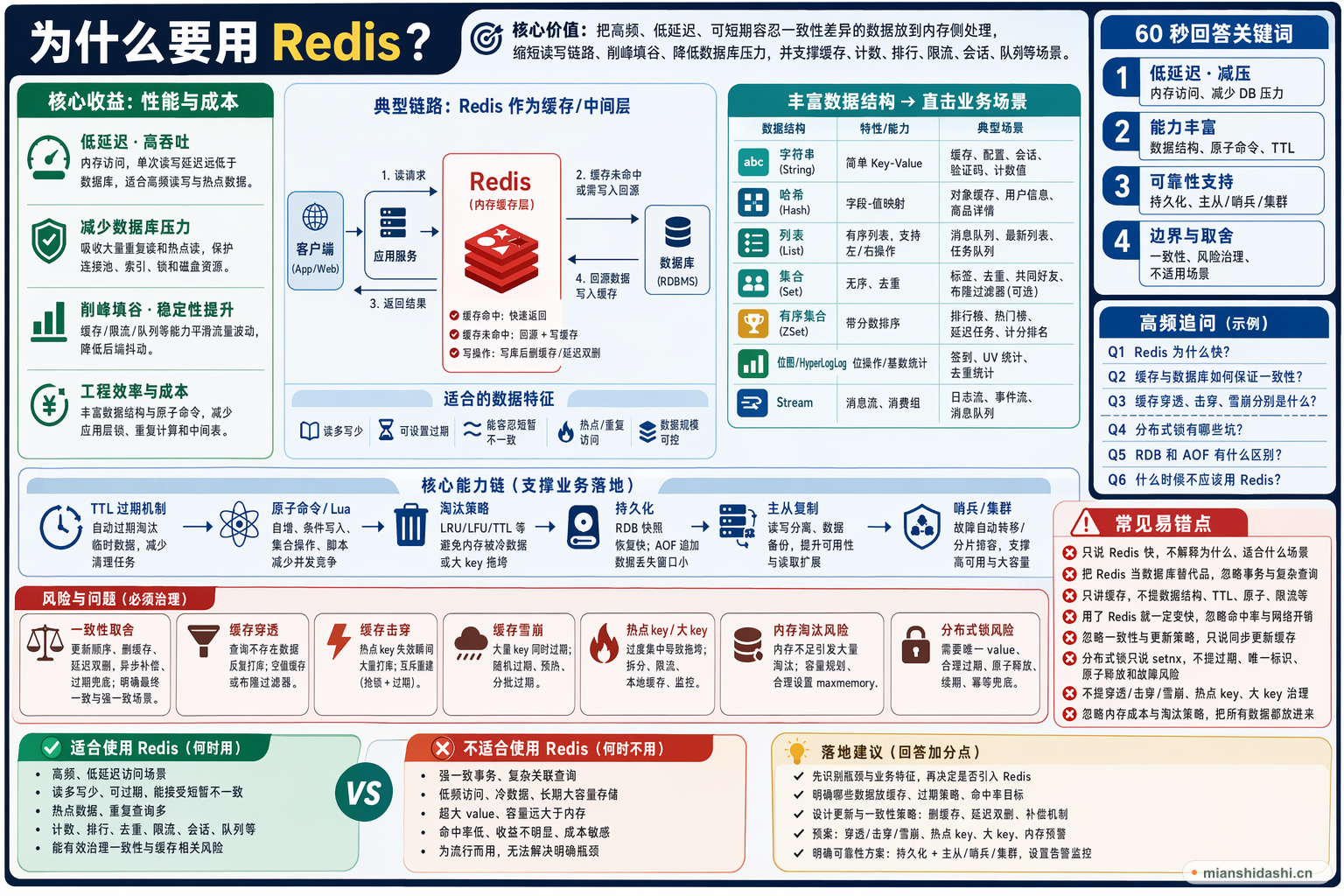
为什么要用redis?
Redis 的核心价值不是更快的数据库,而是把高频、低延迟、可短期容忍一致性差异的数据放到内存侧处理,从而缩短读写链路、削峰填谷、降低关系型数据库压力,并利用丰富数据结构、原子命令、过期机制和高可用能力支撑缓存、计数、排行榜、限流、会话、队列等典型场景。
出现于:阿里巴巴 · 后端开发
真实面经题目 · 原创解析
Redis 的核心价值不是更快的数据库,而是把高频、低延迟、可短期容忍一致性差异的数据放到内存侧处理,从而缩短读写链路、削峰填谷、降低关系型数据库压力,并利用丰富数据结构、原子命令、过期机制和高可用能力支撑缓存、计数、排行榜、限流、会话、队列等典型场景。
回答为什么要用 Redis,我会从业务链路和系统瓶颈来讲。很多系统的核心数据最终仍然落在数据库里,但数据库更擅长事务、复杂查询和持久化,不适合承接大量重复读、热点读和简单高频写。Redis 基于内存访问,单次操作延迟很低,配合字符串、哈希、列表、集合、有序集合等数据结构,可以把缓存、计数器、排行榜、分布式限流、短期状态、会话信息等场景做得更轻。它的 TTL 能自动淘汰临时数据,原子命令能减少并发竞争,持久化和主从、哨兵、集群能提升可恢复性和可用性。但 Redis 不是银弹,使用它要接受缓存和数据库之间的一致性取舍,处理缓存穿透、击穿、雪崩、热点 key、大 key、内存淘汰等问题;分布式锁也要设置过期时间、唯一标识和续期策略,不能把它当作绝对可靠的事务锁。总体上,当系统需要低延迟访问、降低数据库压力、承接热点数据和简单高并发状态时,Redis 很合适;如果数据强一致、查询复杂、容量远大于内存且访问不热点,就不应该为了流行而使用 Redis。
Redis 主要把数据放在内存中,避免频繁磁盘随机 IO,单次读写延迟通常远低于传统数据库查询链路,适合高频访问和热点数据。但性能收益依赖命中率、网络距离、序列化成本和 value 大小,不是接入后必然变快。
Redis 常作为数据库前面的缓存,把重复查询、首页数据、配置数据、商品详情、用户会话等放到缓存中,提高响应速度。它更适合读多写少、可设置过期、能接受短暂不一致或有补偿策略的数据。
在高并发读场景下,大量请求如果直接打到数据库,连接池、索引、锁和磁盘都会成为瓶颈。Redis 可以吸收大量重复读和热点读流量,降低数据库压力,把数据库资源留给事务和复杂查询。尤其在热点商品、配置和用户会话场景中,它能明显减少后端抖动。
Redis 不只是 key-value,还提供哈希、列表、集合、有序集合、位图、HyperLogLog、Stream 等结构,能直接表达计数、去重、排行、消息流、签到、在线状态等业务模型,减少应用层重复造结构。
Redis 的许多命令天然具备原子性,例如自增、条件写入、集合操作和 Lua 脚本执行,适合做计数器、库存预扣、限流窗口和幂等标记等简单并发控制。但原子命令不等于完整分布式事务,跨数据库、消息和缓存的一致性仍要额外设计。
TTL 让临时数据可以自动过期,适合验证码、登录态、短期缓存、幂等 token、限流窗口,减少后台清理任务。设计 TTL 时还要避免大量 key 同时过期,必要时加入随机抖动和预热策略。
常见落地包括缓存、排行榜、计数器、点赞收藏、最近访问列表、轻量队列、分布式限流和短期状态管理。回答时最好把场景和数据结构对应起来,例如排行榜用有序集合,去重用集合或布隆过滤器,短期消息流可以考虑 Stream。
Redis 支持 RDB、AOF 等持久化方式,也可以通过主从复制、哨兵、集群提升可用性和容量。但仍要理解故障切换期间的数据丢失窗口、复制延迟和集群分片带来的多 key 操作限制。
引入 Redis 后系统从单数据源变成缓存加数据库,需要处理更新顺序、删除缓存、延迟双删、异步补偿、过期兜底等一致性问题。不能只说同步更新缓存,要说明失败时如何恢复,并明确哪些场景允许最终一致、哪些场景必须回源数据库。
Redis 不适合替代关系型数据库的复杂事务、复杂关联查询和长期大容量冷数据存储,也不适合无脑承接所有写入。强一致、低频访问、超大 value、成本敏感或容量远超内存的场景要谨慎使用。
除了内存访问,还可以从单线程命令执行减少锁竞争、IO 多路复用、紧凑数据结构编码、避免复杂 SQL 解析和磁盘随机 IO 等方面解释。但网络和序列化仍然有成本。
常见做法是先更新数据库再删除缓存,并结合重试、消息补偿、过期兜底和必要时的延迟双删。强一致场景不应只依赖缓存,要让数据库事实可恢复。
穿透是查询不存在数据绕过缓存反复打库,可用空值缓存或布隆过滤器;击穿是热点 key 失效瞬间打库,可用互斥重建;雪崩是大量 key 同时失效,可用随机过期和预热。
需要唯一 value、防止误删他人锁,设置合理过期时间,释放锁要原子校验和删除,长任务要考虑续期,主从切换和业务超时下仍要靠幂等兜底。
RDB 是快照,恢复快但可能丢失最近数据;AOF 记录写命令,数据丢失窗口更小但写入和恢复成本更高。生产中常结合使用,并按业务容忍度配置刷盘策略。
强一致事务、复杂关联查询、低频冷数据、超大 value、容量远大于内存、命中率低或成本敏感场景都要谨慎。Redis 应解决明确瓶颈,而不是默认加入链路。