真实面经题目 · 原创解析
Redis的List底层实现原理?
Redis List 的底层实现经历过从 ziplist 与 linkedlist 的组合,到 quicklist 统一承载的演进。核心目标不是单纯追求某一种操作最快,而是在两端插入删除、内存占用、缓存友好性和中间位置修改之间做平衡。回答时要讲清:List 是有序、可重复、按插入顺序组织的线性结构,适合队列、栈、简单消息流等场景,但索引访问和中间元素定位不是它的强项。
出现于:阿里巴巴 · 后端开发
真实面经题目 · 原创解析
Redis List 的底层实现经历过从 ziplist 与 linkedlist 的组合,到 quicklist 统一承载的演进。核心目标不是单纯追求某一种操作最快,而是在两端插入删除、内存占用、缓存友好性和中间位置修改之间做平衡。回答时要讲清:List 是有序、可重复、按插入顺序组织的线性结构,适合队列、栈、简单消息流等场景,但索引访问和中间元素定位不是它的强项。
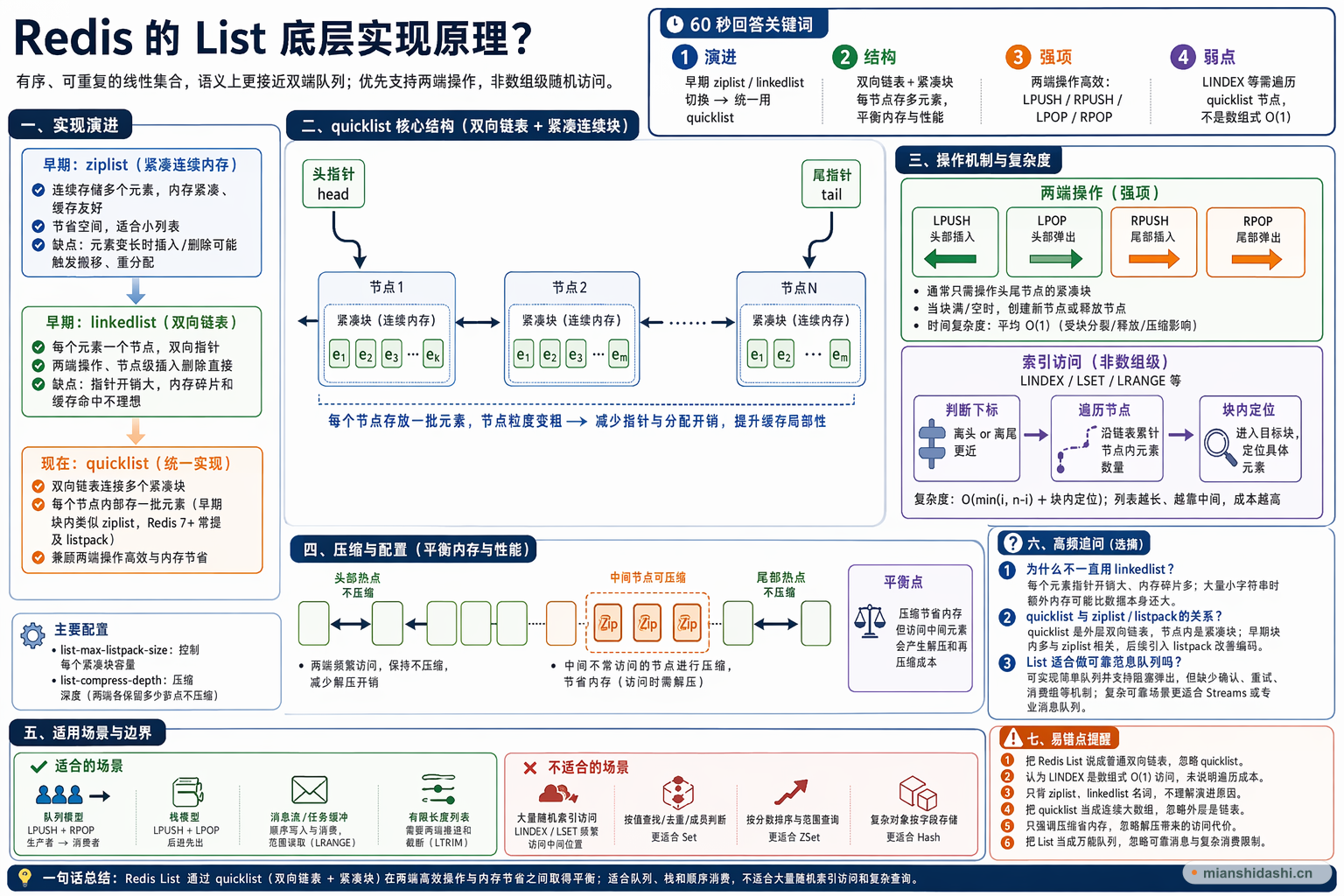
Redis List 早期底层会根据数据规模和元素大小在 ziplist 与 linkedlist 之间选择:ziplist 是紧凑连续内存,节省空间但中间插入删除可能触发搬移;linkedlist 是双向链表,两端操作方便,但每个节点额外指针开销大,内存碎片和缓存命中都不理想。后续 Redis 主要用 quicklist 来实现 List,可以理解为一个双向链表,链表中的每个节点不是只存一个元素,而是存一个紧凑连续的内存块,早期块内类似 ziplist,Redis 7 之后 listpack 背景更常被提到,但回答重点不应陷入版本细节。quicklist 兼顾了两端 LPUSH、RPUSH、LPOP、RPOP 的高效性,又通过块内连续存储降低了大量小元素的内存开销。需要注意的是,List 按下标访问时仍要从头或尾遍历 quicklist 节点,再在块内定位,所以不是数组级别的随机访问。它适合两端频繁操作的队列、栈、有限长度列表,不适合大量按索引随机读写或频繁在中间位置查找修改的场景。
Redis List 是一个有序、可重复的线性集合,语义上更接近双端队列而不是数组。它支持从左端和右端快速插入、弹出,例如 LPUSH、RPUSH、LPOP、RPOP,因此常被用于队列、栈、简单任务缓冲等场景。需要先把语义和实现分开:用户看到的是 List 命令和顺序元素,Redis 内部则需要选择一种既能支持两端操作,又不会因为大量小元素造成巨大内存浪费的数据结构。
早期 Redis List 会在 ziplist 和 linkedlist 两种编码之间切换。ziplist 使用连续内存保存多个元素,优点是紧凑、省内存、缓存局部性好,缺点是元素变长、插入删除时可能引起内存重分配和数据搬移。linkedlist 是传统双向链表,两端操作和节点级插入删除更直接,但每个元素都要承担前后指针、分配器元数据等额外成本。这个阶段的核心矛盾,就是小列表需要省内存,大列表又需要避免连续内存操作代价过高。
后续 Redis 用 quicklist 统一 List 的底层实现。quicklist 可以理解为双向链表连接多个紧凑连续内存块,每个 quicklist 节点内部保存一批元素,而不是一个元素。这样做把 linkedlist 的节点粒度变粗,减少了指针和内存分配开销;同时又不像一个巨大连续数组那样,任何变更都可能移动大量数据。它本质上是在链表灵活性和连续内存紧凑性之间取中间点。
LPUSH 通常会定位到头部 quicklist 节点,把新元素插入该节点内部的紧凑块;如果当前块达到大小限制,就可能创建新的头部节点。RPOP 则从尾部 quicklist 节点删除元素,节点为空后再释放该节点。由于 quicklist 自身保存头尾指针,两端定位非常快,真正的成本主要发生在块内插入删除和偶尔的节点分裂、释放上,所以 List 很适合两端高频写入和消费。
List 支持 LINDEX、LSET、LRANGE 等按位置相关的命令,但这并不意味着它像数组一样具备 O(1) 随机访问。quicklist 要先判断下标更靠近头部还是尾部,然后从较近一端沿链表遍历节点,并根据每个节点内部元素数量累计定位,最后再进入块内找具体元素。因此靠近两端的元素访问较快,越靠近中间且列表越长,定位成本越明显。
quicklist 还引入了节点大小和压缩相关配置,用来控制每个紧凑块容纳多少数据,以及是否对中间节点进行压缩。常见思路是保留两端附近节点不压缩,因为两端最常被 LPUSH、RPOP 等命令访问;中间节点可以压缩以节省内存。这样能在队列型负载中取得较好平衡,但压缩会带来解压和再压缩成本,所以不能只看内存节省,还要结合访问模式判断。
Redis List 的优势是两端操作、顺序消费和有限范围读取,不是复杂查询或随机更新。如果业务需要按成员快速判断是否存在,应考虑 Set;如果要按分数排序和范围查询,应考虑 ZSet;如果需要按字段组织对象,应考虑 Hash。List 用得好的前提是访问路径简单,主要围绕头尾推进;一旦大量依赖中间索引、频繁删除指定值或超长范围扫描,就容易暴露遍历成本。
linkedlist 两端操作很自然,但每个元素都需要独立节点和前后指针,还会产生较多内存分配和碎片。Redis 常保存大量小字符串,如果每个元素都用链表节点包装,额外内存可能比数据本身还大,所以需要 quicklist 这种更紧凑的结构。
quicklist 是 List 的外层组织方式,可以理解为多个紧凑块通过双向链表连接。早期这些块内部常和 ziplist 相关,后续 Redis 引入 listpack 来改善紧凑列表的编码设计。回答重点是 quicklist 的结构思想,不必把答案变成版本背诵。
因为 quicklist 保存头尾指针,LPUSH 可以直接操作头部节点,RPOP 可以直接操作尾部节点,通常不需要扫描整个列表。只要节点块没有触发分裂、释放或压缩处理,路径非常短,符合生产者消费者队列的访问模式。
LINDEX 不是数组下标访问。Redis 会根据下标判断从头还是从尾更近,然后沿 quicklist 节点遍历并累计节点内元素数量,直到定位目标元素。列表越长、目标越靠中间,遍历成本越高,所以不适合大量随机读取。
List 可以实现简单队列,例如一端写入、另一端消费,也能配合阻塞弹出命令降低轮询成本。但它缺少更完整的消息确认、重试、消费组和消息追踪能力。复杂可靠消息场景通常更适合 Streams 或专业消息队列。