真实面经题目 · 原创解析
Claude Code 的 memory 分层设计是什么?
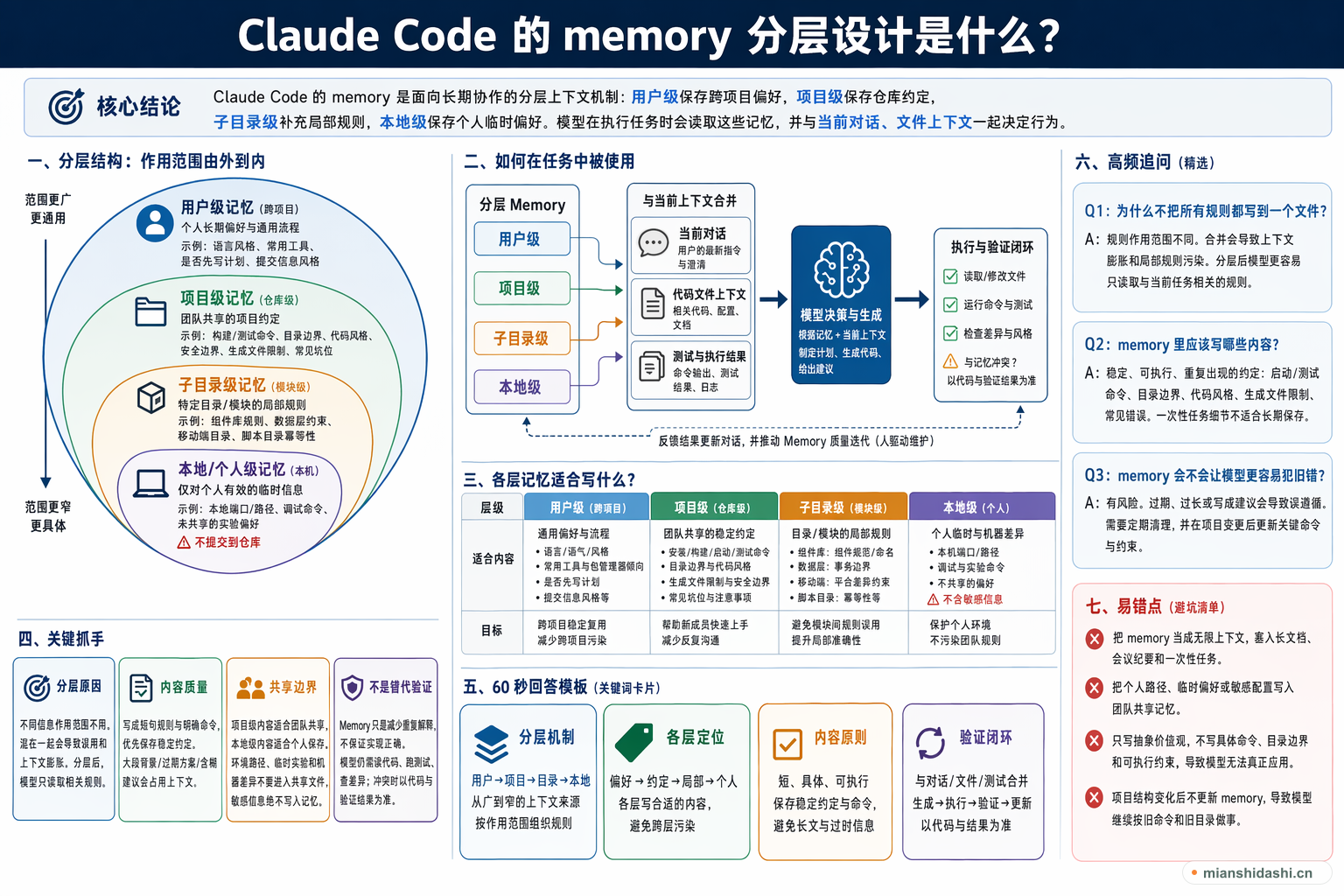
Claude Code 的 memory 可以理解为面向长期协作的分层上下文机制:用户级记忆保存跨项目偏好,项目级记忆保存仓库约定,子目录级记忆补充局部规则,本地级记忆保存个人临时偏好。模型在执行任务时会读取这些记忆,并和当前对话、文件上下文一起决定行为。
出现于:字节跳动 · 后端开发
真实面经题目 · 原创解析
Claude Code 的 memory 可以理解为面向长期协作的分层上下文机制:用户级记忆保存跨项目偏好,项目级记忆保存仓库约定,子目录级记忆补充局部规则,本地级记忆保存个人临时偏好。模型在执行任务时会读取这些记忆,并和当前对话、文件上下文一起决定行为。
回答时可以强调它不是单一记事本,而是分层的上下文来源。用户级 memory 适合写个人长期偏好,例如语言风格、常用工具和通用流程;项目级 memory 适合写团队共享约定,例如构建命令、测试方式、代码风格、安全边界和目录说明;子目录级 memory 适合写某个模块的局部规则,例如组件库、数据层、移动端目录或脚本目录的特殊约束;本地或个人级 memory 适合保存不应提交给团队的临时配置、个人路径和机器差异。好的 memory 应短、具体、可执行,避免塞入大段文档,否则会占用上下文并降低检索效率。
AI 编码工具每次进入仓库时都需要知道项目约定,否则会反复询问或做出不符合团队习惯的改动。Memory 分层的目标,是把稳定、可复用的约定从临时对话中提取出来,让模型在不同任务之间保留协作背景。它解决的是上下文连续性问题,而不是替代代码阅读、测试和审查。
用户级记忆适合保存跨项目都成立的偏好,例如回答语言、是否先写计划、常用包管理器倾向、提交信息风格、是否优先使用某类工具等。这一层不应该写某个仓库的私有命令或业务规则,因为它会影响所有项目。用户级内容越通用,越能减少跨项目污染。
项目级记忆通常放在仓库根部,用于保存团队可共享的项目规则。典型内容包括如何安装依赖、如何启动服务、如何运行测试、目录边界、生成文件限制、代码风格、安全注意事项和常见坑位。它应该像给新成员的高密度工作说明,帮助模型进入项目后少走弯路。
大型仓库中不同目录可能有不同约定,例如前端组件目录强调设计系统,后端服务目录强调事务边界,脚本目录强调幂等性。子目录级记忆让模型进入某个路径时读取更具体的局部规则,避免把一个模块的模式错误套到另一个模块。它本质上是把上下文按代码所有权和技术边界切分。
本地个人记忆适合保存只对当前机器或当前开发者有效的信息,例如本地服务端口、个人调试命令、未共享的实验偏好和不应提交的路径。它应该和团队共享记忆分开,避免把个人环境写进仓库。涉及密钥、令牌和敏感配置时,即使是本地记忆也不应直接保存原文。
因为规则有不同作用范围。全放在一起会导致上下文膨胀,也会让局部约定污染其他模块。分层后,模型更容易只读取与当前任务相关的规则。
适合写稳定、可执行、重复出现的约定,例如启动命令、测试命令、目录边界、代码风格、生成文件限制和常见错误。一次性的任务细节不适合长期保存。
会有这种风险。如果 memory 过期、过长或写得像建议而不是规则,模型可能错误遵循。因此需要定期清理,并在项目变更后更新关键命令和约束。
可以把它当作面向 AI 协作的轻量工程手册,由代码评审和实际问题推动更新。每条规则最好对应可复用的行为约束,而不是记录某次任务流水账。