真实面经题目 · 原创解析
MySQL 索引是如何实现的?
MySQL 的索引实现依赖存储引擎,面试中通常重点讲 InnoDB。InnoDB 主要用 B+Tree 实现索引,主键索引是聚簇索引,叶子节点保存整行数据;二级索引叶子节点保存主键值,通过主键再回表查询完整记录。
出现于:字节跳动 · 后端开发
真实面经题目 · 原创解析
MySQL 的索引实现依赖存储引擎,面试中通常重点讲 InnoDB。InnoDB 主要用 B+Tree 实现索引,主键索引是聚簇索引,叶子节点保存整行数据;二级索引叶子节点保存主键值,通过主键再回表查询完整记录。
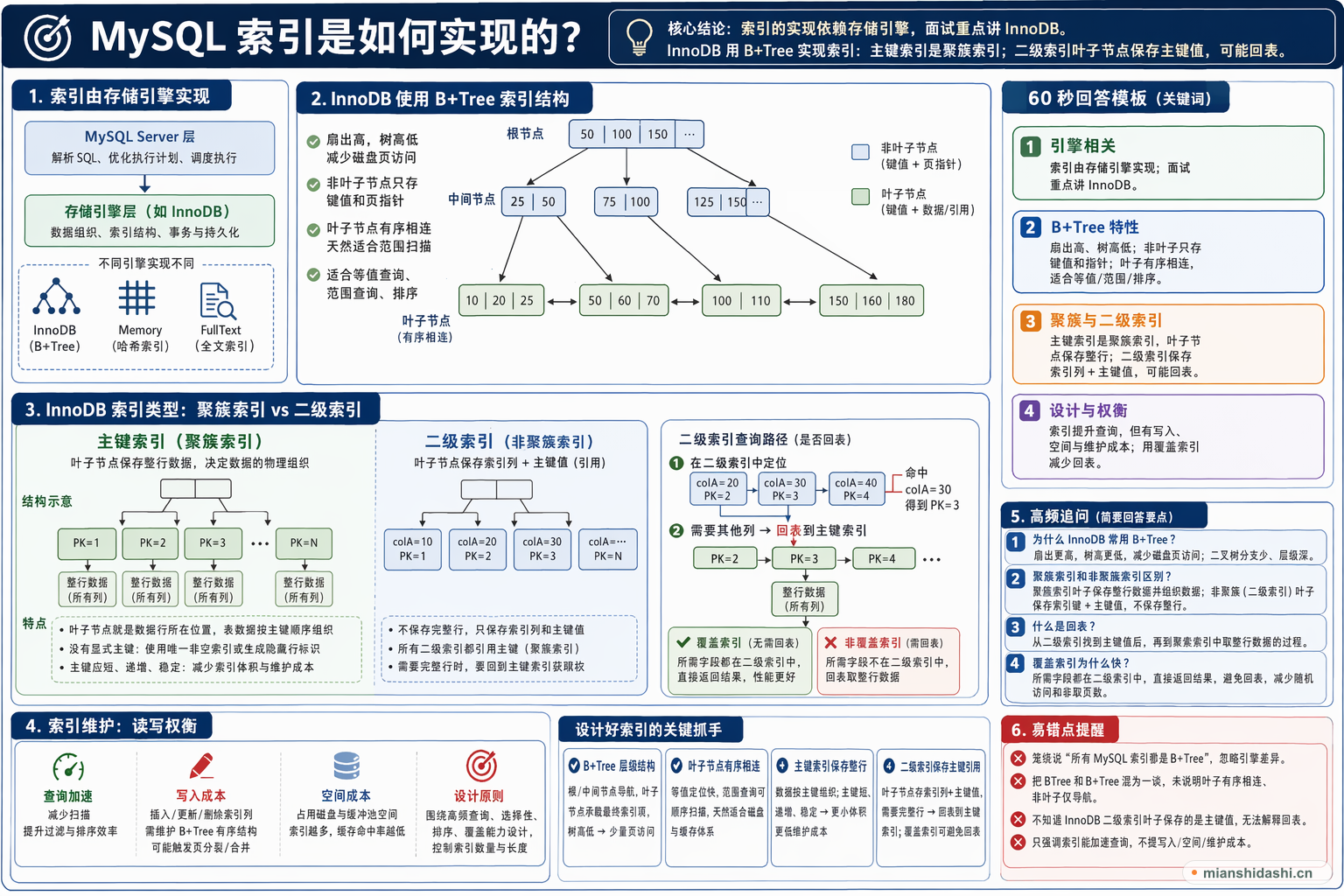
MySQL 索引不是 MySQL Server 层统一固定实现的,而是和存储引擎有关。以 InnoDB 为例,最核心的是 B+Tree 索引。B+Tree 的非叶子节点保存键值和页指针,叶子节点按键值有序并通过链表连接,适合等值查询、范围查询和排序。InnoDB 的主键索引是聚簇索引,数据行就存放在主键索引的叶子节点;普通二级索引的叶子节点保存索引列和主键值,查到主键后如果还需要其他列,就要回到主键索引取整行数据。理解这一点才能解释为什么主键要短且稳定、为什么覆盖索引能减少回表、为什么范围查询适合 B+Tree。
MySQL 的 Server 层负责解析 SQL、优化执行计划和调度执行,真正的数据组织和索引结构由存储引擎负责。因此谈 MySQL 索引实现时要先限定场景,常见回答会以 InnoDB 为主。不同引擎可能有不同实现方式,例如哈希索引、全文索引等,但业务开发和面试中最核心的是 InnoDB 的 B+Tree 索引、聚簇索引和二级索引。
InnoDB 使用 B+Tree 的关键原因是它扇出高、树高低,能够减少磁盘页读取次数。非叶子节点只保存键值和指针,不保存完整数据,因此一个页能容纳更多索引项;叶子节点保存有序数据并互相连接,天然适合范围扫描。相比普通二叉树或红黑树,B+Tree 更适合以页为单位读写的磁盘和缓存体系。
InnoDB 的主键索引是聚簇索引,叶子节点直接保存完整数据行。也就是说,表数据本身按照主键索引组织,而不是索引和数据完全分离。没有显式主键时,InnoDB 会选择唯一非空索引或生成隐藏行标识来组织数据。因为所有二级索引最终都要引用主键,所以主键过长会让二级索引变大,主键频繁变更也会带来额外维护成本。
普通索引也叫二级索引,它的叶子节点不保存整行数据,而是保存二级索引键值和对应主键值。查询如果只需要索引中已有字段,可以通过覆盖索引直接返回;如果还需要其他字段,就要先从二级索引找到主键,再到主键索引中查完整记录,这个过程就是回表。大量回表会显著影响性能,因此设计索引时要考虑查询列是否可以被覆盖。
索引能提升查询速度,但不是越多越好。每次插入、删除、更新索引列时,数据库都要维护对应 B+Tree 的有序结构,可能发生页分裂、页合并和额外写入。索引还会占用磁盘和缓冲池空间,降低缓存命中率。一个好的索引设计应围绕高频查询、过滤选择性、排序需求和覆盖能力展开,同时控制索引数量和字段长度。
B+Tree 扇出更高,树高更低,能减少磁盘页访问次数。二叉树每个节点分支少,在大数据量下层级更深,不适合数据库按页读写的存储模型。
聚簇索引的叶子节点保存完整数据行,数据按索引键组织;非聚簇或二级索引的叶子节点保存索引键和行定位信息。在 InnoDB 中,二级索引保存的是主键值。
使用二级索引查询时,如果需要的列不在该索引中,数据库先通过二级索引找到主键,再用主键到聚簇索引中取完整行,这个额外过程就是回表。
覆盖索引中已经包含查询所需字段,数据库可以直接从二级索引返回结果,避免回表读取完整数据行。它减少随机访问,也降低了读取数据页的数量。