真实面经题目 · 原创解析
为什么选择 Qwen 作为评测裁判,如何做消融实验和指标评估?
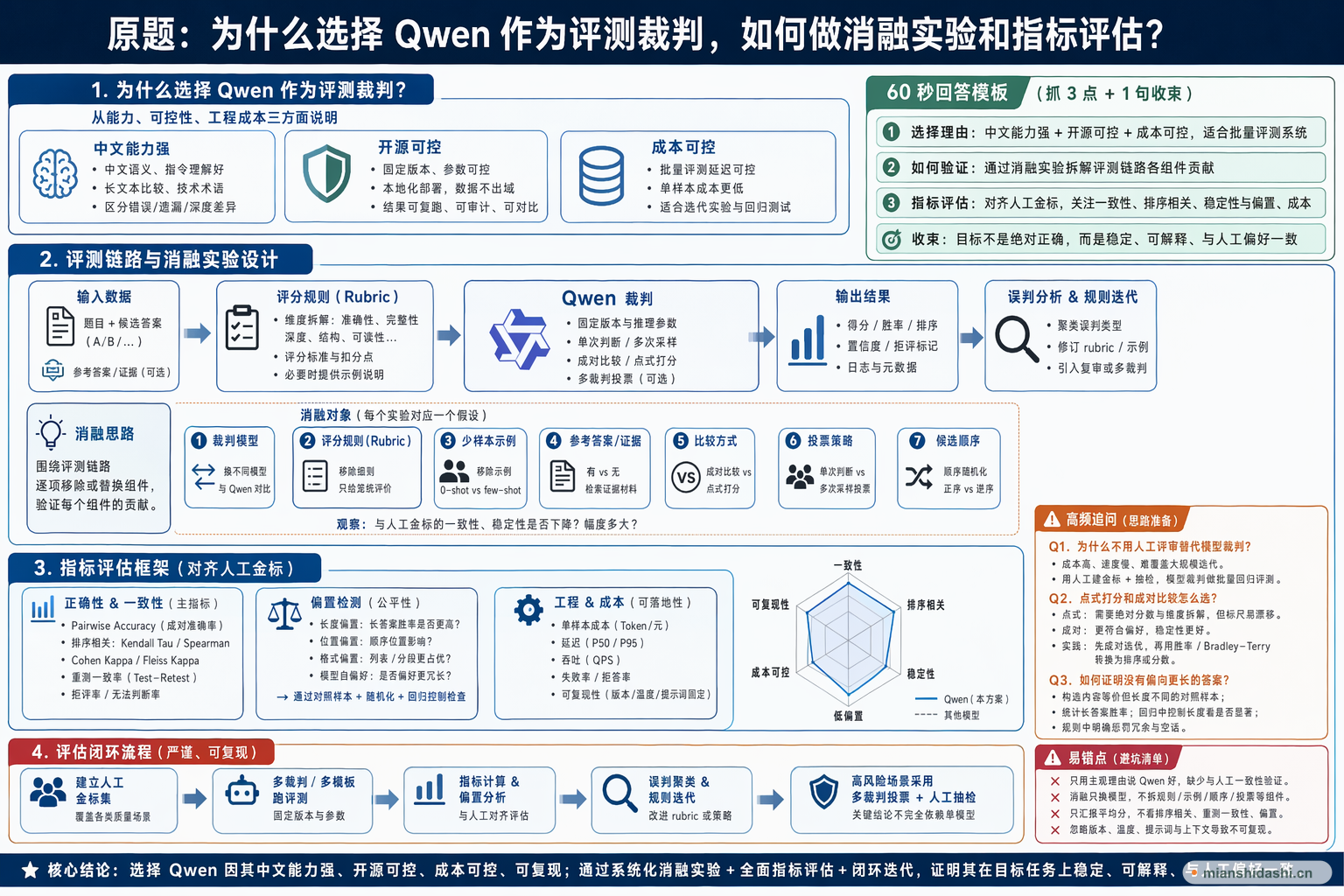
选择 Qwen 作为评测裁判,核心理由通常是中文语义能力、开源可控、成本可控、可本地部署和版本可复现。消融实验要证明裁判选择、提示词、评分规则、样例、检索上下文和投票策略分别带来什么影响,并用人类一致性、排序相关性、稳定性、偏置和成本指标评估。
出现于:字节跳动 · 算法
真实面经题目 · 原创解析
选择 Qwen 作为评测裁判,核心理由通常是中文语义能力、开源可控、成本可控、可本地部署和版本可复现。消融实验要证明裁判选择、提示词、评分规则、样例、检索上下文和投票策略分别带来什么影响,并用人类一致性、排序相关性、稳定性、偏置和成本指标评估。
选择 Qwen 做评测裁判可以从能力、可控性和工程成本三方面回答。能力上,它对中文任务、指令理解和长文本比较有较好适配;可控性上,模型可固定版本、本地部署、隔离业务数据,避免评测结果完全依赖外部服务;成本上,批量评测延迟和单样本成本更可控。为了证明选择合理,需要做消融实验:换不同裁判模型,去掉评分 rubric,去掉少样本示例,比较点式评分和成对比较,比较单次判断和多次投票,比较有无参考答案或检索证据。指标上要对齐人工标注,看 pairwise accuracy、Kendall 或 Spearman 排序相关、Cohen kappa、一致性重测率、长度偏置、位置偏置、拒评率、成本和延迟。最终目标不是证明某个裁判绝对正确,而是证明它在目标任务上稳定、可解释、与人工偏好足够一致。
评测裁判需要理解题目、候选答案、评分规则和业务语境。中文面试题、技术解释和多轮回答常包含术语、隐含要求和表达差异,裁判模型必须能区分事实错误、遗漏、泛泛而谈和结构清晰的深度回答。Qwen 作为中文能力较强且工程生态成熟的开源模型,适合作为可控评测基座,但仍要通过任务集验证。
批量评测最怕裁判版本漂移、外部服务不可控和数据出境风险。固定 Qwen 版本、固定推理参数、固定提示词模板,可以让评测结果可复跑、可审计、可对比。本地化部署还能控制成本与延迟,适合大量候选答案、迭代实验和离线回归测试。
消融要围绕评测链路拆组件,而不是只换一个模型。可以比较不同裁判模型;移除评分细则,只给笼统评价;移除少样本标注;移除参考答案或证据材料;把成对比较换成单答案打分;关闭多次采样投票;打乱候选答案顺序。每个变化都要观察与人工评测的一致性和稳定性是否下降。
裁判评估不能只看平均分。成对比较可用 pairwise accuracy,排序任务可用 Kendall tau 或 Spearman correlation,一致性可用 Cohen kappa 或重复评测一致率。还要检查长度偏置、位置偏置、模型自偏好、格式偏置和过度惩罚简短答案的问题。一个好裁判应当既接近人工判断,又不被表面风格轻易带偏。
更严谨的流程是先建立人工金标集,覆盖高质量、低质量、事实错、结构好但内容浅、内容对但表达差等样本;再用不同裁判和模板跑评测;最后分析误判簇,修订 rubric 或引入复审机制。对于高风险结论,应采用多裁判投票或人工抽检,而不是完全依赖单个模型。
人工评审质量高但成本高、速度慢、难以覆盖大规模迭代。更现实的做法是用人工建立金标集和抽检机制,用模型裁判承担批量回归评测,再用不一致样本反向改进规则。
点式打分适合需要绝对分数和维度拆解的场景,但标尺漂移明显;成对比较更符合偏好判断,稳定性通常更好。实际可以先成对选优,再把胜率或 Bradley-Terry 模型转换成排序。
可以构造内容等价但长度不同的对照样本,统计长答案胜率;也可以在回归中控制答案长度,看长度是否仍显著影响得分。评分规则里要明确惩罚冗余和空话。
不一定。多裁判能降低单模型偶然误判,但会增加成本,并且如果多个裁判共享相似偏置,投票也可能一起错。关键是看与人工金标的一致性是否真实提升。